异步协程编程可以在IO操作时大幅提高处理速度,在爬虫爬取信息时有大量的IO操作,正是异步协程的良好运用场景。
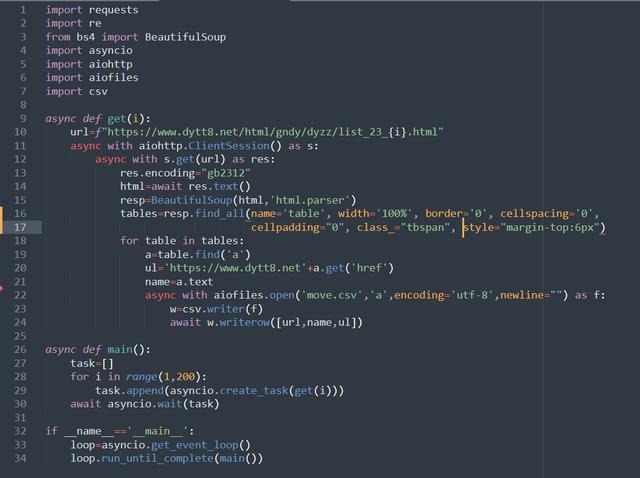
代码图片如下:
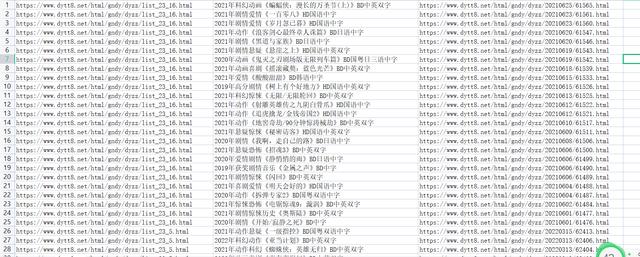
提取出的文件信息如下:
具体代码:
import requests
import re
from bs4 import BeautifulSoup
import asyncio
import aiohttp
import aiofiles
import CSV
async def get(i):
url=f"https://www.dytt8.net/html/gndy/dyzz/list_23_{i}.html"
async with aiohttp.ClientSession() as s:
async with s.get(url) as res:
res.encoding="gb2312"
html=await res.text()
resp=BeautifulSoup(html,'html.parser')
tables=resp.find_all(name='table', width='100%', border='0', cellspacing='0',
cellpadding="0", class_="tbspan", style="margin-top:6px")
for table in tables:
a=table.find('a')
ul='https://www.dytt8.net'+a.get('href')
name=a.text
async with aiofiles.open('move.csv','a',encoding='utf-8',newline="") as f:
w=csv.writer(f)
await w.writerow()
async def main():
task=
for i in range(1,200):
task.append(asyncio.create_task(get(i)))
await asyncio.wait(task)
if __name__=='__main__':
loop=asyncio.get_event_loop()
loop.run_until_complete(main())
这写这一爬虫过程中运用了:aiohttp模块异步请求网页,运用BeautiulSoup来提取所需信息,用CSV文件来存储提取出的信息,异步协程编程可在IO请求时节省大量时间,正是爬虫所需